AXIOM Benchmarks
Verified results across model sizes. Train 70B on enterprise GPU or 13B completely FREE on Kaggle.
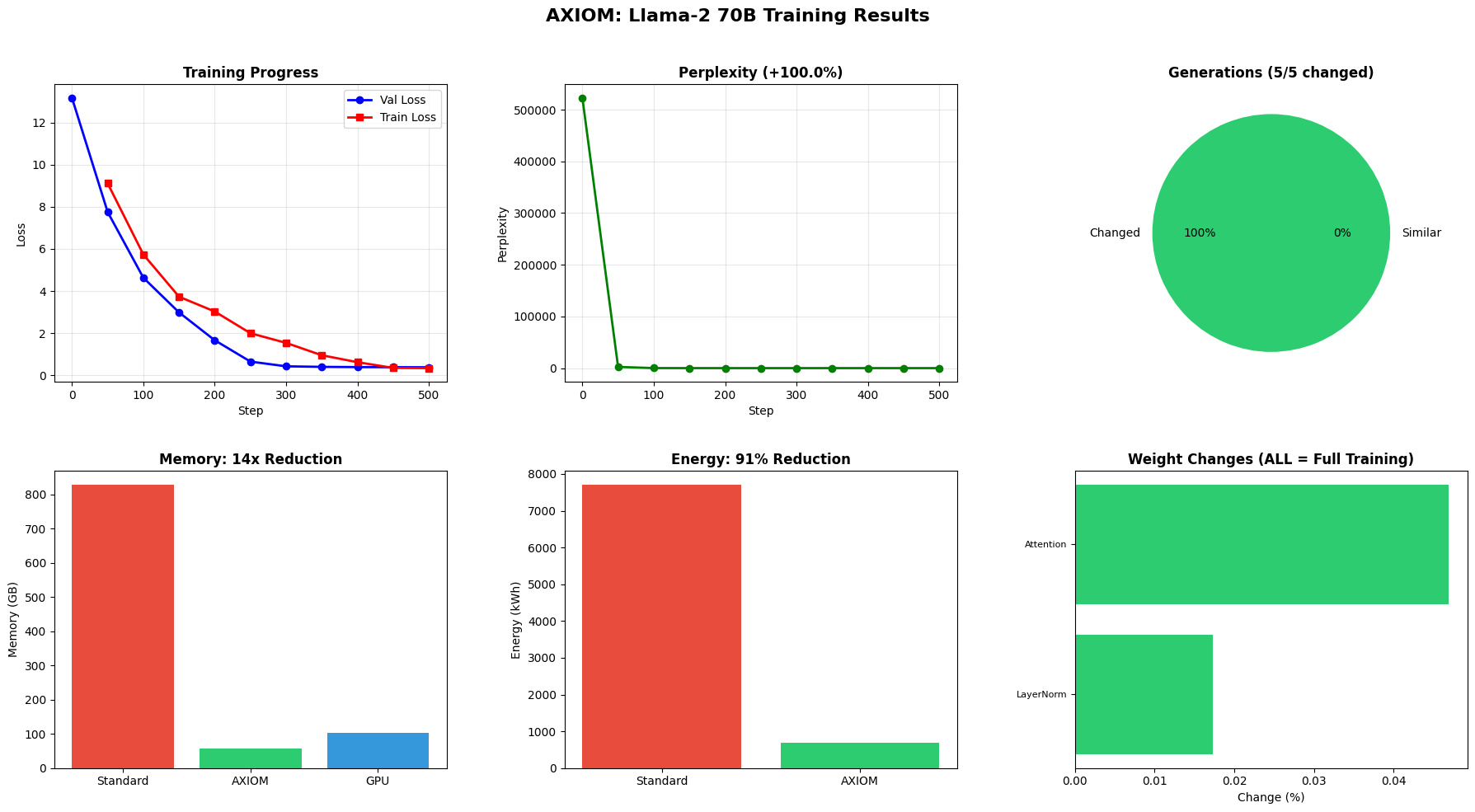
Llama-2 70B
Blackwell GPU (102GB)
Llama-2 13B
Kaggle T4 (16GB) - $0 cost
Llama-2 70B — Previously Needed 11 GPUs
Now trains on a single GPU with AXIOM
Benchmark Results (Click to Expand)
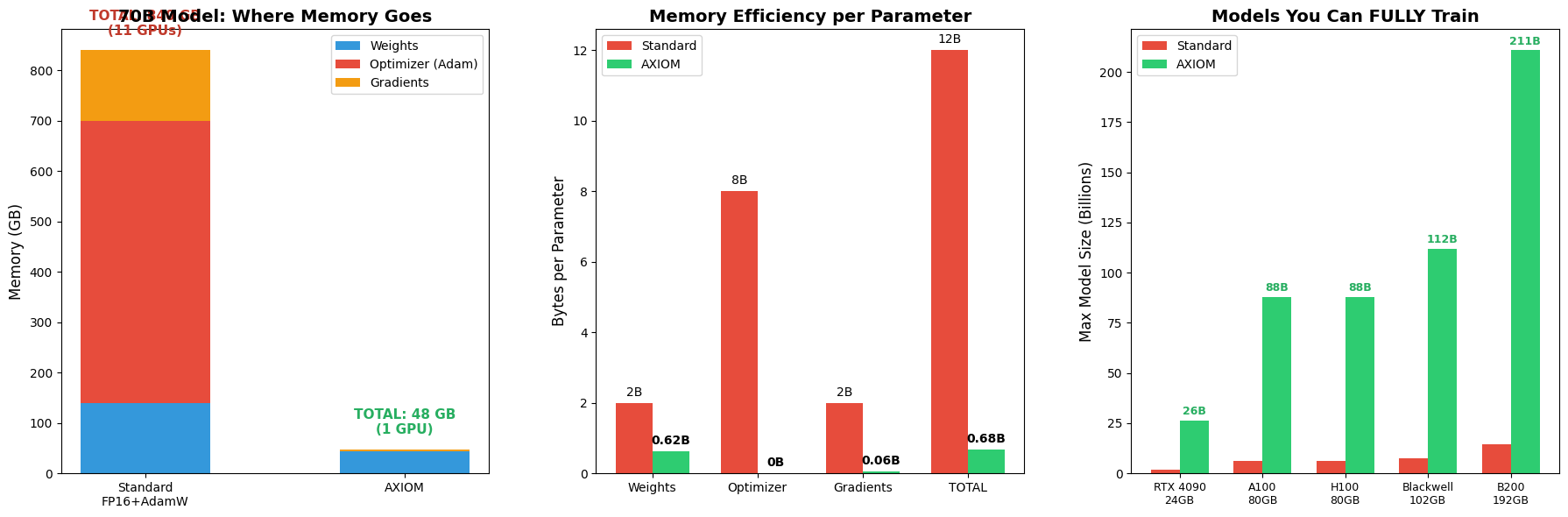
Memory Breakdown: 840GB → 53GB
Training Dashboard: Loss, PPL, Memory
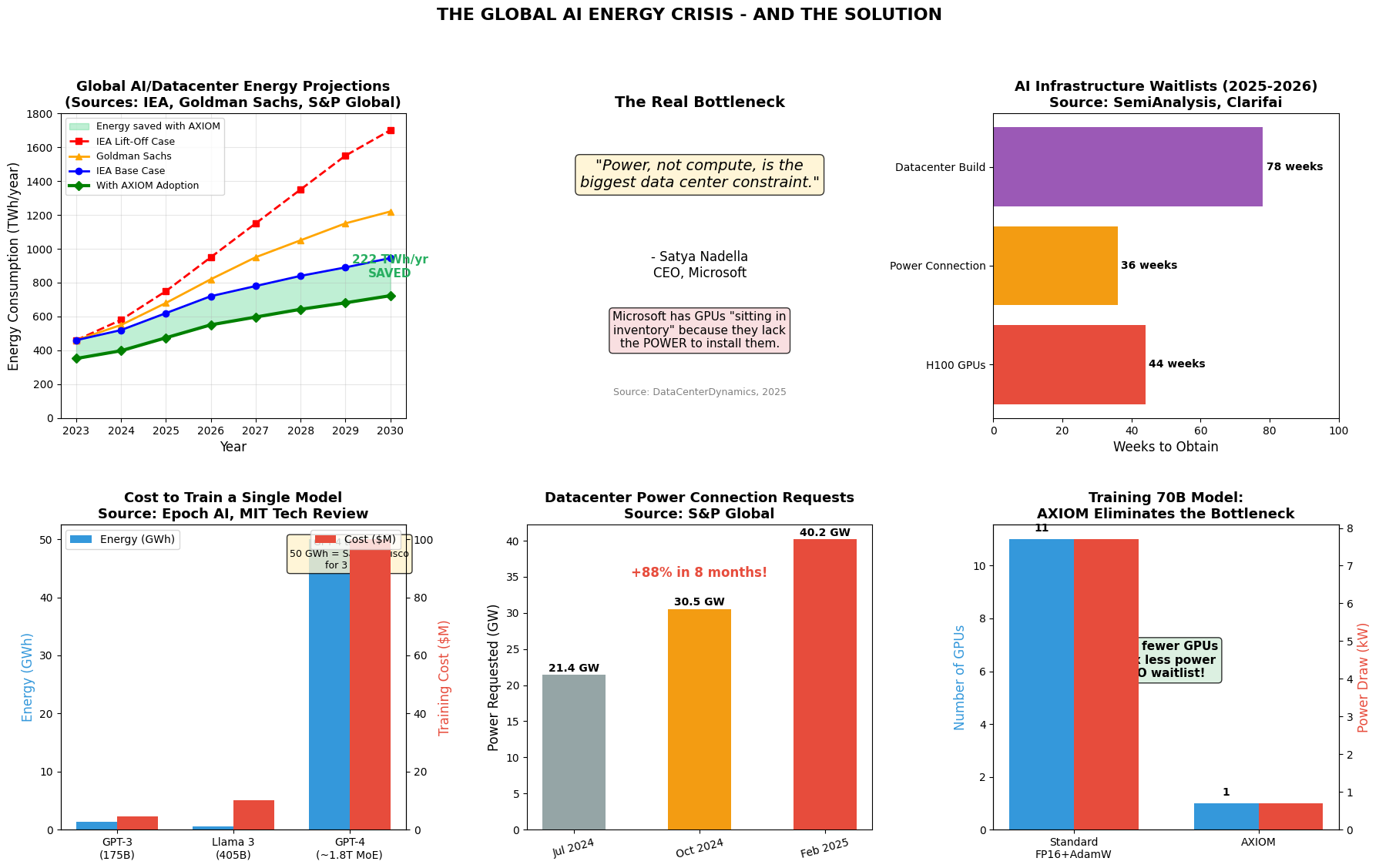
Energy Crisis: Global Datacenter Projections
Proof of Full Training
Weight Changes (Verified)
All layer types show weight changes = real learning, not frozen model
Generation Changes: 5/5
Training Convergence
Perplexity Improvement
Step-by-Step Training Progression
| Step | Train Loss | Val Loss | Perplexity | Memory (GB) | Tok/s |
|---|---|---|---|---|---|
| 50 | 9.11 | 7.75 | 2320.4 | 57.6 | 63 |
| 100 | 5.73 | 4.63 | 102.7 | 57.6 | 51 |
| 200 | 3.03 | 1.67 | 5.3 | 57.6 | 47 |
| 300 | 1.54 | 0.43 | 1.5 | 57.6 | 45 |
| 400 | 0.62 | 0.39 | 1.5 | 57.6 | 45 |
| 500 | 0.34 | 0.38 | 1.5 | 57.6 | 44 |
GPU: NVIDIA RTX PRO 6000 Blackwell Server Edition (102 GB) — Peak memory: 57.6 GB
The Global AI Energy Crisis
If AXIOM Were Widely Adopted by 2030:
For Big Tech: The Competitive Advantage
Current Reality
- • GPUs sitting IDLE due to power constraints
- • GPU waitlists: 36-52 weeks even with unlimited budget
- • Each frontier training run: 20-25 MW for 3 months
- • Datacenter build time: 18+ months
With AXIOM
- Train 11× more models (same power budget)
- Eliminate GPU waitlists (1 GPU vs 11)
- Use stranded/idle GPU assets
- 121× more training runs possible
Democratizing AI: Who Can Train What
| Hardware | VRAM | Standard | AXIOM |
|---|---|---|---|
| Gaming Laptop (RTX 4070) | 8 GB | 0.6B | 9B |
| Gaming Desktop (RTX 4090) | 24 GB | 1.8B | 26B |
| Workstation (RTX 6000 Ada) | 48 GB | 3.6B | 53B |
| Cloud (A100 80GB) | 80 GB | 6B | 88B |
| Cloud (H100 80GB) | 80 GB | 6B | 88B |
| Blackwell | 102 GB | 7.6B | 112B |
| B200 | 192 GB | 14.4B | 211B |
Students & Academia
Train LLaMA-7B on a desktop. PhD research no longer limited by compute.
Startups
Train 70B+ on single cloud GPU. Monthly cost: ~$2,500 vs $500,000+.
Developing Nations
No datacenter infrastructure required. Local language models become feasible.
Enterprise
Train proprietary models on-premise. No cloud dependency for sensitive data.
Memory Efficiency (Bytes per Parameter)
| Component | Standard | AXIOM | Compression |
|---|---|---|---|
| Weights | 2B | 0.75B | 2.7x |
| Optimizer | 8B | 0B | ∞ |
| Gradients | 2B | 0.06B | 33x |
| Total | 12B | 0.81B | 14.8x |
Quick Start
Run It Yourself
Ready to train larger models?
15.7x memory compression. 91% energy savings. 3 lines of code.